5. Electroacoustics
Exploring how sound is captured, processed, digitised, and reproduced through technology
Electroacoustics is the branch of acoustics concerned with the conversion of sound into electrical signals, and vice versa. It encompasses the study and design of devices such as microphones, loudspeakers, amplifiers, and related equipment. Electroacoustics is foundational to virtually all forms of modern music making, recording, and reproduction.
At its core, electroacoustics depends on transduction: the process of converting energy from one form to another. A microphone transduces acoustic pressure variations (sound) into varying electrical voltages. A loudspeaker does the reverse, converting electrical signals back into acoustic pressure variations. Together, these two transducers, and the signal processing chain between them, form the backbone of almost every contemporary musical and audio experience.
Electroacoustics is a subdiscipline of acoustics, alongside room acoustics and instrument acoustics, which we explored in acoustics. While the physical principles of sound propagation remain the same, electroacoustics introduces electrical and electronic phenomena that shape how sound is captured, modified, transmitted, and reproduced.
A brief history¶
The history of electroacoustics begins in the late nineteenth century. Alexander Graham Bell’s invention of the telephone in 1876 demonstrated that speech could be converted to electrical signals and transmitted over wires. Thomas Edison’s phonograph (1877) showed that sound could be recorded and played back mechanically. The development of the carbon microphone, the vacuum tube amplifier, and the moving-coil loudspeaker in the early twentieth century made electrical sound reproduction practical.
The introduction of the condenser (capacitor) microphone in the 1920s, followed by developments in magnetic recording, FM radio, and high-fidelity audio in the mid-twentieth century, transformed music production and broadcasting. Today, digital signal processing, miniaturised microelectronics, and wireless transmission continue to reshape the field.
Why electroacoustics matters for music¶
For musicians, music psychologists, and music technologists, understanding electroacoustics is essential for several reasons:
- Recording and production: every recorded piece of music has passed through microphones, amplifiers, and loudspeakers. The characteristics of these devices shape the timbral qualities of the recording.
- Live sound: concert halls and clubs rely on electroacoustic reinforcement. The choice and placement of microphones and speakers determines how a performance sounds to the audience.
- Research: studying music psychology often involves presenting stimuli through headphones or speakers; understanding the characteristics of these devices is important for interpreting results.
- Electronic instruments: synthesisers, electric guitars, and digital instruments all involve electroacoustic transduction at some stage of the signal chain.
Digitised audio is also the usual input to computational descriptors of pitch and harmony (see machine listening) and connects back to music-theoretical representations in harmony and melody.
Transduction¶
A transducer is any device that converts energy from one form to another. In electroacoustics, the primary interest is in devices that convert between acoustic energy (pressure waves in air) and electrical energy (varying voltages or currents).
We can describe the relationship between cause and effect in an electroacoustic system as follows:
The key transducers in this chain are the microphone (acoustic → electrical) and the loudspeaker (electrical → acoustic). The intermediate stages (preamplifier, signal processing, power amplifier) operate entirely in the electrical domain.
Transduction principles¶
Different electroacoustic transducers exploit different physical phenomena to achieve energy conversion:
- Electromagnetic induction: a conductor moving in a magnetic field generates an electrical current (used in dynamic microphones and moving-coil loudspeakers).
- Electrostatic / capacitive: changes in the distance between two charged plates alter the capacitance and produce a voltage (used in condenser microphones and electrostatic loudspeakers).
- Piezoelectric: certain crystals and ceramics generate an electrical charge when mechanically deformed (used in contact microphones and some transducers).
- Magnetostrictive and other effects: used in some specialist transducers.
Each principle has characteristic strengths and limitations in terms of frequency response, sensitivity, dynamic range, and cost.
Microphones¶
A microphone is a transducer that converts acoustic pressure variations in the surrounding air into a corresponding electrical signal. The quality, type, and placement of a microphone profoundly influence the character of any recording or live sound system.
Dynamic (moving-coil) microphones¶
The dynamic microphone is the most widely used type in live sound. Its operating principle is electromagnetic induction:
- Sound waves cause a thin diaphragm to vibrate.
- A voice coil attached to the diaphragm moves within the field of a permanent magnet.
- This movement induces an electrical current in the coil, proportional to the velocity of the diaphragm.
Advantages: robust, tolerant of high sound pressure levels, requires no external power supply, relatively inexpensive.
Disadvantages: limited high-frequency response due to the inertia of the diaphragm and coil assembly; generally lower sensitivity than condenser microphones.
Typical examples include the Shure SM58 (vocal microphone) and Shure SM57 (instrument microphone), which are industry standards in live sound.
Condenser (capacitor) microphones¶
The condenser microphone uses an electrostatic principle:
- The diaphragm forms one plate of a capacitor, with a fixed backplate as the other.
- The capacitor is maintained at a fixed charge (either by a battery or by phantom power supplied through the microphone cable).
- Sound waves cause the diaphragm to move, varying the distance between the plates and hence the capacitance.
- This change in capacitance at constant charge produces a varying voltage, which is the output signal.
Advantages: very flat and extended frequency response, high sensitivity, low self-noise, available in small diaphragm (pencil) and large diaphragm varieties.
Disadvantages: requires power (phantom power at 48 V, or internal battery); more fragile than dynamic microphones; more expensive.
Condenser microphones are the preferred choice for studio recording of acoustic instruments, voices, and orchestras. Large-diaphragm condensers (e.g., Neumann U87) are a staple of professional studios.
Ribbon microphones¶
The ribbon microphone uses a thin corrugated metallic ribbon suspended in a magnetic field:
- Sound waves cause the ribbon to vibrate within the magnetic field.
- The movement of the ribbon induces a voltage by electromagnetic induction, similar to a dynamic microphone, but the ribbon itself is both the diaphragm and the conductor.
Advantages: natural and smooth high-frequency roll-off, excellent transient response, often described as having a warm and vintage sound character. Ribbon microphones are inherently bidirectional (figure-8 polar pattern).
Disadvantages: fragile ribbon element; lower output level, requiring a high-gain preamplifier; sensitive to wind and plosive sounds; some classic ribbon microphones should not be connected to phantom power (though modern active ribbon microphones require it).
MEMS microphones¶
MEMS (Micro-Electro-Mechanical Systems) microphones are semiconductor-based transducers fabricated using integrated circuit manufacturing techniques. They are used in smartphones, laptops, hearing aids, and other consumer devices where miniaturisation is essential. Their electroacoustic performance has improved dramatically in recent years, and they are increasingly found in professional measurement applications as well.
Microphone polar patterns¶
A polar pattern (or directivity pattern) describes how sensitive a microphone is to sounds arriving from different directions. It is typically represented as a plot of sensitivity versus angle, in polar coordinates.
The main polar patterns are:
- Omnidirectional: equal sensitivity in all directions. Captures the full acoustic environment, including room reflections.
- Cardioid: most sensitive in front, least sensitive at the rear (heart-shaped pattern). The most common pattern for live sound and studio recording. Offers some rejection of unwanted sounds from behind.
- Supercardioid / Hypercardioid: narrower front pickup than cardioid, with a small rear lobe. More directional; useful in noisy environments.
- Figure-8 (bidirectional): picks up equally from front and rear, with strong rejection from the sides. Used in ribbon microphones and as a component in mid-side recording techniques.
In practice, polar patterns vary with frequency: most directional microphones are more omnidirectional at low frequencies and become more directional as frequency increases. The plots below illustrate idealised patterns.
Source
import numpy as np
import matplotlib.pyplot as plt
theta = np.linspace(0, 2 * np.pi, 360)
# Standard polar pattern formulae (values clipped at 0 for plotting)
omni = np.ones_like(theta)
cardioid = np.clip(0.5 + 0.5 * np.cos(theta), 0, 1)
supercard = np.clip(0.37 + 0.63 * np.cos(theta), 0, 1)
hypercard = np.clip(0.25 + 0.75 * np.cos(theta), 0, 1)
figure8 = np.abs(np.cos(theta))
patterns = {
"Omnidirectional": omni,
"Cardioid": cardioid,
"Supercardioid": supercard,
"Hypercardioid": hypercard,
"Figure-8": figure8,
}
fig, axes = plt.subplots(1, 5, subplot_kw=dict(polar=True), figsize=(14, 3))
colors = ['steelblue', 'darkorange', 'seagreen', 'firebrick', 'purple']
for ax, (name, pattern), color in zip(axes, patterns.items(), colors):
ax.plot(theta, pattern, color=color, linewidth=2)
ax.fill(theta, pattern, alpha=0.15, color=color)
ax.set_theta_zero_location('N') # 0 degrees at the top (front of microphone)
ax.set_theta_direction(-1) # Clockwise
ax.set_ylim(0, 1)
ax.set_yticks([0.5, 1.0])
ax.set_yticklabels([])
ax.set_xticks(np.radians([0, 90, 180, 270]))
ax.set_xticklabels(['0°', '90°', '180°', '270°'], fontsize=7)
ax.set_title(name, fontsize=9, pad=10)
plt.suptitle('Idealised Microphone Polar Patterns', fontsize=12, y=1.02)
plt.tight_layout()
plt.show()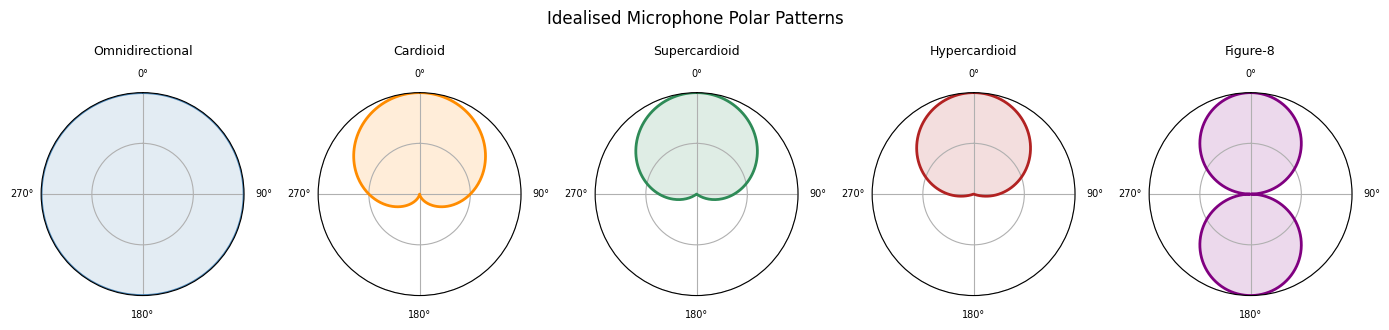
Microphone frequency response¶
The frequency response of a microphone describes how its output sensitivity varies across the audio frequency range. An ideal microphone would have a perfectly flat frequency response, meaning it captures all frequencies equally. In practice, every microphone design imposes some deviation from flat response.
- Dynamic microphones typically show a reduced sensitivity at high frequencies due to the inertia of the coil–diaphragm assembly, and may have a moderate presence peak (a boost around 3–8 kHz) to enhance clarity of voice or instruments.
- Condenser microphones generally provide a flatter, more extended high-frequency response. Large-diaphragm condensers often have a subtle presence peak around 8–12 kHz.
- Ribbon microphones exhibit a gentle high-frequency roll-off, which contributes to their characteristically warm sound.
At low frequencies, proximity effect is a common phenomenon in directional (cardioid, figure-8) microphones: the bass response increases when the sound source is very close to the microphone (within 30–60 cm). This effect is exploited by vocalists and broadcasters to achieve a richer, fuller sound, but can be a problem when recording at close range if unwanted bass boost is not desired.
Source
import numpy as np
import matplotlib.pyplot as plt
freq = np.logspace(np.log10(20), np.log10(20000), 1000)
def smooth_step(x, x0, width):
"""Logistic-style smooth transition centred on x0."""
return 1 / (1 + np.exp(-(x - x0) / width))
# Simulate idealised frequency responses (in dB, relative to 1 kHz)
# Dynamic: slight presence peak ~5 kHz, high-frequency roll-off above 12 kHz
dynamic = (
2.5 * np.exp(-((np.log10(freq) - np.log10(5000)) ** 2) / (2 * 0.15 ** 2))
- 6 * smooth_step(np.log10(freq), np.log10(12000), 0.15)
)
# Condenser: very flat, small presence peak ~10 kHz, slight HF extension
condenser = (
1.5 * np.exp(-((np.log10(freq) - np.log10(10000)) ** 2) / (2 * 0.2 ** 2))
- 2 * smooth_step(np.log10(freq), np.log10(18000), 0.1)
)
# Ribbon: warm roll-off starting around 8 kHz
ribbon = (
-0.5 * np.log10(freq / 1000)
- 4 * smooth_step(np.log10(freq), np.log10(8000), 0.2)
)
# Low-frequency roll-off common to most mics (high-pass due to housing)
lf_rolloff = -10 * smooth_step(-np.log10(freq), -np.log10(80), 0.15)
dynamic += lf_rolloff
condenser += lf_rolloff
ribbon += lf_rolloff
fig, ax = plt.subplots(figsize=(10, 4))
ax.semilogx(freq, dynamic, label='Dynamic (moving-coil)', color='steelblue', linewidth=2)
ax.semilogx(freq, condenser, label='Condenser (capacitor)', color='darkorange', linewidth=2)
ax.semilogx(freq, ribbon, label='Ribbon', color='seagreen', linewidth=2)
ax.axhline(0, color='grey', linestyle='--', linewidth=0.8, label='0 dB reference')
ax.set_xlim(20, 20000)
ax.set_ylim(-15, 8)
ax.set_xlabel('Frequency (Hz)', fontsize=11)
ax.set_ylabel('Relative level (dB)', fontsize=11)
ax.set_title('Idealised Frequency Responses of Microphone Types', fontsize=12)
ax.set_xticks([50, 100, 200, 500, 1000, 2000, 5000, 10000, 20000])
ax.set_xticklabels(['50', '100', '200', '500', '1k', '2k', '5k', '10k', '20k'])
ax.grid(True, which='both', alpha=0.3)
ax.legend(fontsize=10)
plt.tight_layout()
plt.show()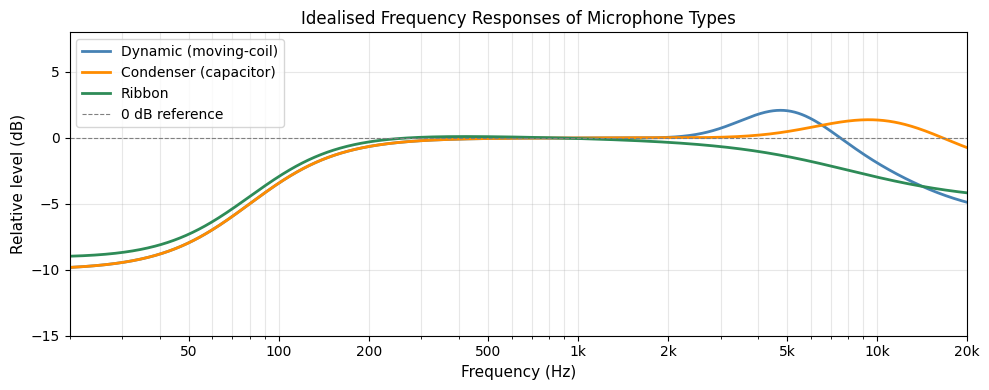
Microphone specifications¶
When comparing or selecting microphones, the following specifications are most important:
| Specification | Description | Typical values |
|---|---|---|
| Sensitivity | Output voltage for a given sound pressure level (usually 1 Pa / 94 dB SPL). Higher (less negative) is more sensitive. | −60 to −30 dBV/Pa |
| Frequency response | Range and flatness of frequency coverage. | 20 Hz – 20 kHz (±3 dB) |
| Self-noise (equivalent noise level) | The inherent electronic noise of the microphone, expressed as dB SPL. Lower is better. | 10–30 dB (A-weighted) |
| Maximum SPL | The highest sound pressure level the microphone can handle before distortion. | 120–150 dB SPL |
| Dynamic range | Maximum SPL minus self-noise. | 90–130 dB |
| Polar pattern | The directional sensitivity pattern. | Omni, cardioid, figure-8, etc. |
| Output impedance | The electrical impedance of the microphone output. | 50–600 Ω (professional) |
Loudspeakers¶
A loudspeaker (often simply called a speaker) converts electrical signals into acoustic pressure variations. It is the final electroacoustic transducer in most audio reproduction systems.
Moving-coil (dynamic) loudspeakers¶
The moving-coil loudspeaker is by far the most common loudspeaker type. Its operation is the electromagnetic inverse of the dynamic microphone:
- An alternating electrical current flows through a voice coil suspended in a permanent magnetic field.
- The interaction of the current and the magnetic field produces a force on the coil (Lorentz force), causing it to move back and forth.
- The coil is attached to a cone (diaphragm), whose movement creates pressure waves in the surrounding air.
Most practical loudspeaker systems use several drivers, each optimised for a different frequency range:
- Woofer: handles low frequencies (bass), typically 20–500 Hz. Large diameter cone (15–40 cm) for efficient low-frequency radiation.
- Midrange driver: covers middle frequencies (500 Hz – 5 kHz), where much of the energy of speech and music is concentrated.
- Tweeter: handles high frequencies (5–20 kHz). Small diameter diaphragm (2–4 cm) for extended high-frequency response.
- Subwoofer: dedicated low-frequency driver (20–200 Hz) for cinema, music production, and concert sound reinforcement.
A crossover network routes the appropriate frequencies to each driver, ensuring that each operates within its optimal range.
Electrostatic loudspeakers¶
Electrostatic loudspeakers use the same capacitive principle as condenser microphones, in reverse. A thin conductive diaphragm is stretched between two perforated stators. A high electrical field is maintained between the stators and the diaphragm; applying an audio signal to the stators causes the diaphragm to vibrate. Electrostatic loudspeakers are valued for their extremely low distortion and transient accuracy, but are expensive, large, and require high-voltage power supplies.
Headphones and earphones¶
Headphones are miniature loudspeakers worn directly on or in the ears. They are available in several configurations:
- Over-ear (circumaural): pads surround the ears; typically offer good passive isolation and a more natural sound stage.
- On-ear (supra-aural): pads rest on the ears; more compact but often less isolating.
- In-ear monitors (IEMs): fit inside the ear canal; used extensively in professional monitoring on stage, as well as in consumer earbuds.
- Bone-conduction headphones transmit sound through vibrations of the skull bones rather than through the ear canal. Small transducers placed on the cheekbones (just in front of the ears) convert the electrical signal into mechanical vibration, which reaches the inner ear directly.
Most headphones use dynamic (moving-coil) drivers; high-end models may use planar magnetic or electrostatic elements. The acoustics of headphones differ fundamentally from loudspeakers in a room: headphones bypass the effects of room acoustics and the pinnae, which can affect perceived spatial image. This makes them attractive for controlled listening experiments in music psychology research, but means that recordings mixed on headphones may translate differently to loudspeakers.
Loudspeaker frequency response and sensitivity¶
Like microphones, loudspeakers are characterised by their frequency response. Unlike microphones, achieving a flat frequency response across the full audio range from a single transducer is very difficult, which is why multi-driver systems with crossovers are standard.
The sensitivity of a loudspeaker is typically specified as the sound pressure level (in dB SPL) produced at a distance of 1 metre when driven with 1 watt (or 2.83 V into an 8 Ω load). A loudspeaker with higher sensitivity requires less amplifier power to achieve a given loudness.
The plot below shows idealised frequency responses for different loudspeaker configurations, illustrating how each driver covers a different portion of the audio spectrum.
Source
import numpy as np
import matplotlib.pyplot as plt
freq = np.logspace(np.log10(20), np.log10(20000), 1000)
def bandpass_response(f, f_low, f_high, slope_low=24, slope_high=24):
"""Simulate a bandpass driver response with gentle Butterworth-like slopes."""
low_shelf = 1 / np.sqrt(1 + (f_low / f) ** slope_low)
high_shelf = 1 / np.sqrt(1 + (f / f_high) ** slope_high)
return 20 * np.log10(low_shelf * high_shelf + 1e-10)
subwoofer = bandpass_response(freq, 25, 200, slope_low=24, slope_high=12)
woofer = bandpass_response(freq, 50, 1000, slope_low=12, slope_high=12)
midrange = bandpass_response(freq, 300, 5000, slope_low=12, slope_high=12)
tweeter = bandpass_response(freq, 3000, 22000, slope_low=12, slope_high=24)
fig, ax = plt.subplots(figsize=(10, 4))
ax.semilogx(freq, subwoofer, label='Subwoofer (20–200 Hz)', color='navy', linewidth=2)
ax.semilogx(freq, woofer, label='Woofer (50 Hz – 1 kHz)', color='steelblue', linewidth=2)
ax.semilogx(freq, midrange, label='Midrange (300 Hz – 5 kHz)', color='darkorange', linewidth=2)
ax.semilogx(freq, tweeter, label='Tweeter (3–20 kHz)', color='firebrick', linewidth=2)
ax.axhline(-3, color='grey', linestyle='--', linewidth=0.8, label='−3 dB point')
ax.set_xlim(20, 20000)
ax.set_ylim(-40, 5)
ax.set_xlabel('Frequency (Hz)', fontsize=11)
ax.set_ylabel('Relative level (dB)', fontsize=11)
ax.set_title('Idealised Frequency Responses of Loudspeaker Drivers', fontsize=12)
ax.set_xticks([50, 100, 200, 500, 1000, 2000, 5000, 10000, 20000])
ax.set_xticklabels(['50', '100', '200', '500', '1k', '2k', '5k', '10k', '20k'])
ax.grid(True, which='both', alpha=0.3)
ax.legend(fontsize=9)
plt.tight_layout()
plt.show()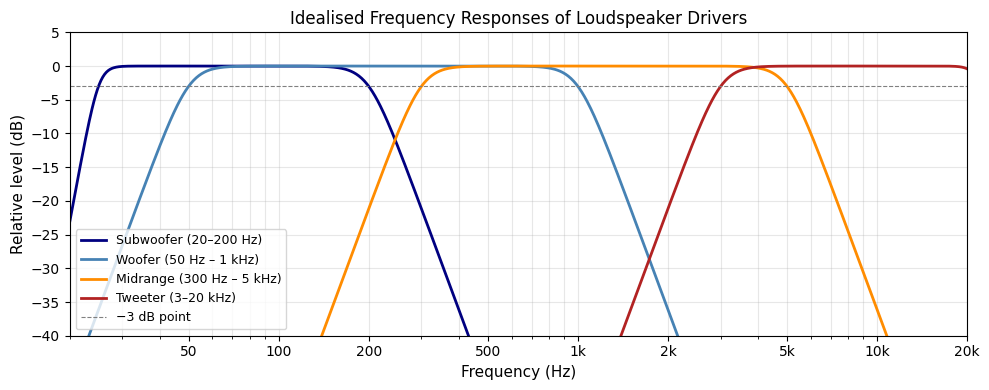
Loudspeaker placement and room interaction¶
A loudspeaker does not operate in isolation: it interacts strongly with the room in which it is placed. Reflections from walls, floor, and ceiling combine with the direct sound at the listener’s ears, modifying the perceived frequency response and spatial character.
- Bass modes (room modes): at low frequencies, rooms support standing waves (modes) that result in uneven bass response at different positions. Subwoofer placement and room treatment are important for minimising these effects.
- Boundary loading: placing a loudspeaker close to a wall increases bass output due to the reflected sound reinforcing the direct sound. Corner placement further increases bass due to loading from two or three room boundaries.
- Speaker placement for stereo: a symmetric equilateral triangle arrangement, with the listener at the apex and the two speakers at the base, is a common starting point for stereo listening. The speakers should ideally be placed away from room boundaries and on stands at ear height.
These effects mean that the same loudspeaker can sound quite different in different rooms, and that acoustic treatment of the room and careful speaker placement are as important as the choice of loudspeaker itself.
Amplifiers¶
An amplifier is a device that increases the power, voltage, or current of an electrical signal. In an audio signal chain, amplification is necessary because microphones produce very small voltages (millivolts) while loudspeakers require much larger voltages and currents to produce audible sound.
Signal levels¶
Audio signals are conventionally described in terms of their level, measured in decibels relative to a reference:
- Microphone level (−60 to −40 dBu): the output of a microphone before amplification. Very small voltages; requires a preamplifier (preamp) to boost to line level.
- Instrument level (−20 to −10 dBu): the output of electric guitars, basses, and some keyboards. Higher than microphone level but typically unbalanced; requires a DI (direct injection) box or instrument input.
- Line level (0 dBu for professional, −10 dBV for consumer): the standard operating level for studio and consumer equipment such as mixers, effects processors, and CD players.
- Speaker level (many volts): the amplified signal driving a passive loudspeaker.
Preamplifiers¶
A preamplifier (preamp) amplifies a microphone-level signal to line level. A high-quality microphone preamplifier is essential for maintaining a low noise floor: if the preamp introduces noise, subsequent amplification will amplify that noise along with the signal. The key specification of a microphone preamplifier is its equivalent input noise (EIN), typically measured in dBu.
Modern audio interfaces for recording contain built-in microphone preamplifiers. Professional recording studios may use high-quality external preamps (e.g., API 312, Neve 1073) that contribute to the characteristic sound of recordings made in those facilities.
Power amplifiers¶
A power amplifier takes a line-level signal and amplifies it to the voltages and currents needed to drive a loudspeaker. Power amplifiers are characterised by their output power (in watts) and their efficiency. Modern Class D amplifiers (switching amplifiers) offer high efficiency (>80%) and are used widely in portable speakers, home theatre systems, and professional sound reinforcement.
Phantom power¶
Most condenser microphones require an external power source to maintain the charge on the capacitor element. Phantom power (standardised at 48 V DC, denoted +48V) is supplied through the microphone cable by the preamplifier or audio interface. It is called ‘phantom’ because it does not interfere with the audio signal, which travels as a differential (balanced) pair on the same conductors. Dynamic and ribbon microphones generally do not require phantom power (and some older ribbon microphones can be damaged by it).
The signal chain¶
The signal chain refers to the complete path that an audio signal follows from its acoustic source to the listener’s ears. Understanding the signal chain is essential for troubleshooting problems and for making informed decisions about equipment choice and configuration.
A typical recording signal chain involves the following stages:
In live sound, the signal chain is similar but may include a digital mixing console and distribution to multiple loudspeakers covering different zones of the venue.
Balanced and unbalanced connections¶
Professional audio equipment uses balanced connections (XLR or TRS connectors) to carry signals over long cable runs without picking up interference. A balanced connection carries the audio signal twice: once as a normal polarity signal and once with the polarity inverted. Any electromagnetic interference picked up along the cable affects both conductors equally; at the receiving end, the differential input of the preamplifier or interface cancels the common-mode noise, leaving only the audio signal. This is known as common-mode rejection.
Consumer and instrument-level connections are often unbalanced (TS connectors, RCA/phono connectors), which are more susceptible to interference over long cable runs.
Gain staging¶
Gain staging is the practice of setting appropriate signal levels at each stage of the signal chain to maximise signal-to-noise ratio while avoiding clipping (distortion from exceeding the maximum signal level). Each stage should receive a signal that is neither so weak that noise becomes significant, nor so strong that it clips. In digital audio systems, clipping above 0 dBFS (decibels relative to full scale) causes severe digital distortion.
Signal processing¶
Signal processing is the field concerned with analysing, modifying, and synthesising signals such as sound, images, and scientific measurements. In electroacoustics and audio engineering, it is essential for improving sound quality, extracting information, and adapting audio for specific applications.
Signal processing can be done in both the analog and digital domain. Key aspects of signal processing in audio include:
- Amplification: increasing the strength of electrical signals so they can drive loudspeakers or be recorded at usable levels.
- Filtering: removing unwanted frequencies (such as noise or hum) or enhancing desired frequency ranges. Filters can be low-pass, high-pass, band-pass, or notch filters.
- Equalisation (EQ): adjusting the balance between frequency components to shape the tonal quality of audio signals.
- Dynamic range compression: reducing the difference between the loudest and quietest parts of a signal to make audio more consistent and prevent distortion.
- Noise reduction: techniques such as gating, spectral subtraction, or adaptive filtering to minimise background noise.
- Effects processing: adding reverberation, delay, chorus, distortion, or other effects to enhance or creatively alter the sound.
- Modulation: changing aspects of the signal such as amplitude, frequency, or phase for transmission or synthesis.
Signal processing is used in microphones, mixing consoles, audio interfaces, hearing aids, mobile devices, loudspeaker management systems, and music production software. It enables clear communication, high-fidelity reproduction, and creative sound design.
Digital audio¶
Digital audio extends the electroacoustic signal chain into storage, editing, transmission, and reproduction in computers and digital devices. The basic principles are simple, but they strongly affect fidelity, workflow, and file size.
Sound vs audio¶
It is useful to distinguish between sound and audio. Sound refers to vibrations travelling through a material medium, while audio is the technological representation used to capture, store, process, and reproduce those vibrations. Audio can exist in both analog and digital forms, and acts as the intermediary between transducers such as microphones and loudspeakers.
Digitisation¶
Digitisation is the process of converting physical sound into digital audio signals using an Analog-to-Digital Converter (ADC). This involves two main steps: sampling and quantisation.
First, the continuous sound wave is measured at regular intervals, producing a stream of samples. The number of measurements per second is the sampling rate. Next, each sampled value is rounded to the nearest value that can be represented by a fixed number of bits, known as the bit depth. The result is a stream of numbers that can be stored, processed, and transmitted by digital systems.
The plots below illustrate these two ideas: one shows how different sampling rates capture a continuous waveform, and the other shows how different bit depths quantise sampled values.
Sampling rate¶
The sampling rate is the number of samples per second taken from a continuous signal to create a discrete signal. According to the Nyquist–Shannon sampling theorem, the sampling rate must be at least twice the highest frequency present in the signal to reconstruct it accurately. This minimum limit is known as the Nyquist frequency.
The CD standard uses 44,100 Hz, which can represent frequencies up to 22,050 Hz. Professional recording often uses 48 kHz, 96 kHz, or higher. Higher sampling rates can reduce aliasing and leave more headroom for some processing tasks, but they also increase file size and CPU load.
Bit depth¶
The audio bit depth is the amount of data used to represent each individual sample in a digital audio signal. Bit depth determines the precision of the stored amplitude values. Higher bit depths allow more accurate representation of the original sound, resulting in lower quantisation noise and a greater dynamic range.
- Low bit depth (for example 8-bit): few available amplitude levels, which can introduce audible distortion and noise.
- 16-bit: the CD standard, allowing 65,536 possible amplitude values.
- 24-bit: common in professional recording, offering over 16 million levels and much greater practical headroom.
- 32-bit float: used in some modern recorders and production workflows, providing extremely large headroom and flexibility during recording and post-production.
Digital audio interfaces¶
A digital audio interface (often simply called an audio interface) is the device that connects microphones, instruments, and other audio sources to a computer for recording, and routes the computer’s audio output to loudspeakers or headphones for playback.
The audio interface contains:
- Microphone preamplifiers: one or more high-quality preamps to bring microphone-level signals up to line level.
- Analog-to-digital converters (ADCs): convert the analog input signal to a digital bitstream at the chosen sample rate and bit depth.
- Digital-to-analog converters (DACs): convert the digital output from the computer back to an analog signal for monitoring.
- Headphone amplifier: a low-impedance amplifier to drive headphones from the monitor output.
- Digital audio connectivity: USB, Thunderbolt, FireWire, or Dante connections to the computer.
The converters in an audio interface apply the principles of sampling and quantisation described above. The quality of the ADCs and DACs, together with the selected sample rate and bit depth, affects the transparency, noise floor, and working headroom of a recording system.
Real-time audio, buffers, and latency¶
In a digital audio workstation (DAW), live performance setup, or real-time synthesis patch, audio is processed in blocks (buffers) of samples rather than as one infinite stream. The buffer size (or block size), together with the sampling rate, sets how often the computer must finish a round of processing: a smaller buffer means lower latency (less delay between input and output) but leaves less time per block and raises CPU load; a larger buffer is more forgiving for heavy plug-ins but increases latency and can make timing feel sluggish when monitoring yourself or playing virtual instruments.
Typical sources of round-trip latency include A/D and D/A conversion, buffering in the driver and application, and digital signal processing in the chain. Interfaces and drivers often report an input and output latency; total monitoring delay is what matters for performers. Many systems offer direct monitoring (analogue path from input to headphones, bypassing the computer) to avoid hearing yourself late. Understanding buffers links the digital audio principles above—sample rate, bit depth, CPU cost—to everyday decisions in recording, streaming, and live electronics.
Source
import numpy as np
import matplotlib.pyplot as plt
frequency = 1
amplitude = 1
sampling_rates = [5, 10, 20, 50]
x = np.linspace(0, 2 * np.pi, 1000)
continuous_wave = amplitude * np.sin(2 * np.pi * frequency * x)
plt.figure(figsize=(12, 2))
plt.plot(x, continuous_wave, label='Continuous sine wave', color='blue', alpha=0.7)
for rate in sampling_rates:
sampled_x = np.linspace(0, 2 * np.pi, rate, endpoint=False)
sampled_wave = amplitude * np.sin(2 * np.pi * frequency * sampled_x)
plt.scatter(sampled_x, sampled_wave, label=f'Sampled points ({rate} Hz)', zorder=5)
plt.title('Effect of Different Sampling Rates on a Sine Tone')
plt.xlabel('x')
plt.ylabel('Amplitude')
plt.axhline(0, color='black', linewidth=0.5, linestyle='--')
plt.legend()
plt.grid()
plt.show()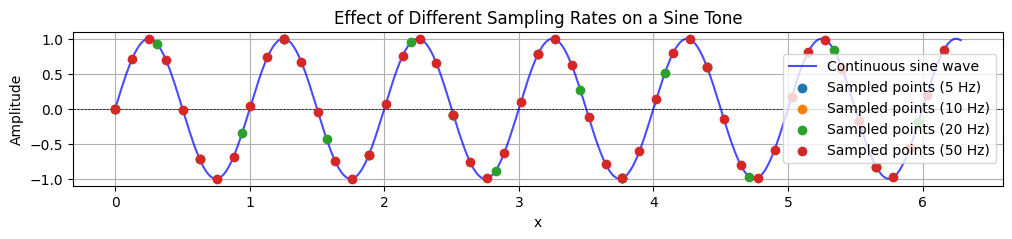
Source
import numpy as np
import matplotlib.pyplot as plt
# Illustrate quantisation at different bit depths
t = np.linspace(0, 2 * np.pi, 500)
signal = np.sin(t)
bit_depths = [2, 4, 8, 16]
fig, axes = plt.subplots(1, 4, figsize=(14, 3), sharey=True)
for ax, bits in zip(axes, bit_depths):
levels = 2 ** bits
quantised = np.round(signal * (levels / 2)) / (levels / 2)
ax.plot(t, signal, color='grey', linewidth=1, alpha=0.5, label='Original')
ax.step(t, quantised, color='steelblue', linewidth=1.2, where='mid', label=f'{bits}-bit')
ax.set_title(f'{bits}-bit ({levels} levels)', fontsize=9)
ax.set_xlim(0, 2 * np.pi)
ax.set_ylim(-1.3, 1.3)
ax.set_xticks([])
ax.legend(fontsize=7, loc='upper right')
ax.grid(alpha=0.3)
axes[0].set_ylabel('Amplitude', fontsize=10)
fig.suptitle('Quantisation at Different Bit Depths', fontsize=12)
plt.tight_layout()
plt.show()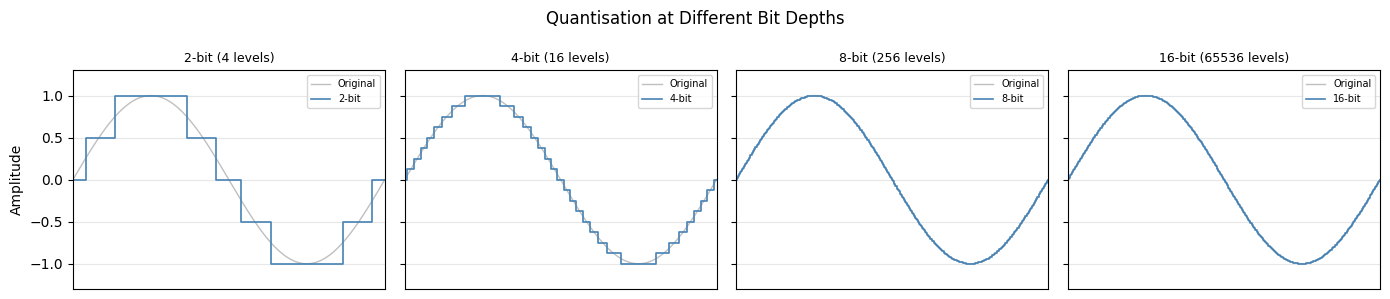
Audio compression and file formats¶
Digital audio must also be stored and transmitted efficiently. Audio containers are file formats that store digital audio data together with metadata such as track information, album art, and artist details. Common containers include WAV and AIFF, both of which typically store uncompressed, high-quality audio.
Some containers, such as MKV, can hold uncompressed or compressed audio alongside video and metadata. Others, such as MP4, often store compressed audio, frequently together with video.
It is important to distinguish between the container and the compression method. Audio file compression reduces the file size of digital audio to make storage and transmission more efficient. This is different from dynamic range compression used in mixing and mastering. There are two main types:
- Lossless compression: preserves all original audio data, allowing perfect reconstruction, as in FLAC and ALAC.
- Lossy compression: removes some audio data, usually components that are less perceptible to human hearing, to achieve smaller file sizes, as in MP3 and AAC.
| Format | Compression Type | Typical Use | Quality |
|---|---|---|---|
| WAV, AIFF | None | Recording, editing | Excellent |
| FLAC | Lossless | Archiving, hi-fi | Excellent |
| AAC | Lossy | Streaming | Good |
AAC generally gives better quality than MP3 at a similar file size, which is why it is commonly preferred for streaming. Open ecosystems also offer alternatives such as the Ogg container and related codecs.
Electroacoustic systems in practice¶
Studio recording¶
A professional recording studio provides a controlled acoustic environment with carefully treated rooms, high-quality microphones, preamplifiers, and monitoring loudspeakers. Common studio microphone setups include:
- Close-miking: placing the microphone close to the instrument (within 30 cm). Minimises room reflections and maximises the direct-to-reverberant ratio. Subject to proximity effect in directional microphones.
- Room miking: placing microphones further away (1–5 m) to capture the acoustic of the room as well as the instrument. Used for orchestral recording and when a natural, spacious sound is desired.
- Stereo miking techniques: using a pair of microphones to capture a stereo image. Common techniques include:
- XY (coincident pair): two cardioid microphones angled at 90–135°, with their capsules at the same point. Mono-compatible.
- ORTF: two cardioid microphones spaced 17 cm apart and angled at 110°, mimicking the spacing and angle of human ears.
- A/B (spaced pair): two omnidirectional microphones spaced 0.5–3 m apart. Wide stereo image but phase issues can affect mono compatibility.
- Mid-Side (M-S): a cardioid microphone (mid) combined with a figure-8 microphone (side), with the side signal added to and subtracted from the mid signal to create left and right channels. The stereo width is adjustable after recording.
Live sound reinforcement¶
In live sound, the goal is to amplify performers so that the entire audience can hear clearly without the system causing feedback or colouring the sound. Key considerations include:
- Feedback: occurs when the microphone picks up sound from the loudspeaker, which is re-amplified, creating a loop. Controlling feedback requires careful choice of polar patterns, microphone placement relative to speakers, and equalisation.
- Monitor speakers (wedges/in-ear monitors): on-stage speakers facing the performers, allowing them to hear themselves and the rest of the ensemble.
- Line arrays: modern large-venue sound systems use line arrays, vertically stacked arrays of loudspeaker elements that produce a more controlled directional pattern, allowing even coverage of large audiences while minimising sound reaching the stage and ceiling.
Measurement microphones¶
Electroacoustic measurement uses specialised measurement microphones (typically small-diaphragm condensers with precisely flat, omnidirectional response) to characterise rooms, loudspeakers, and other acoustic systems. Room correction software (such as Dirac Live or Sonarworks) uses measurement microphone recordings to create correction filters that flatten the in-room frequency response of a loudspeaker system at the listening position.
Acoustic feedback and the Larsen effect¶
The Larsen effect, commonly known as audio feedback, is the howling or screeching sound produced when a microphone picks up the output of the loudspeaker it is feeding. This forms a closed acoustic-electrical loop in which any signal is continuously amplified. The frequency at which feedback occurs depends on the combined frequency response of the entire system (microphone, amplifier, loudspeaker, and room). Understanding electroacoustics helps engineers manage and prevent feedback through equalisation (notch filters), microphone placement, and careful gain management.
Source
import numpy as np
import matplotlib.pyplot as plt
# Illustrate the concept of signal-to-noise ratio and dynamic range
# for different microphone types (idealised)
mic_types = ['Dynamic\n(SM58)', 'Condenser\n(U87)', 'Ribbon\n(R84)', 'MEMS\n(smartphone)']
self_noise = [18, 12, 22, 32] # dB SPL (A-weighted)
max_spl = [150, 132, 130, 120] # dB SPL
dynamic_range = [m - n for m, n in zip(max_spl, self_noise)]
x = np.arange(len(mic_types))
width = 0.35
fig, ax = plt.subplots(figsize=(9, 4))
bars1 = ax.bar(x - width/2, max_spl, width, label='Maximum SPL (dB)', color='steelblue', alpha=0.85)
bars2 = ax.bar(x + width/2, self_noise, width, label='Self-noise (dB SPL)', color='darkorange', alpha=0.85)
ax.set_xticks(x)
ax.set_xticklabels(mic_types, fontsize=10)
ax.set_ylabel('dB SPL', fontsize=11)
ax.set_title('Microphone Self-Noise, Maximum SPL, and Dynamic Range (Idealised)', fontsize=11)
ax.legend(fontsize=10)
ax.grid(axis='y', alpha=0.3)
# Annotate dynamic range
for i, (dr, ms, sn) in enumerate(zip(dynamic_range, max_spl, self_noise)):
ax.annotate(
f'DR: {dr} dB',
xy=(i, (ms + sn) / 2),
ha='center', va='center',
fontsize=8, color='black',
bbox=dict(boxstyle='round,pad=0.2', facecolor='white', edgecolor='grey', alpha=0.8)
)
plt.tight_layout()
plt.show()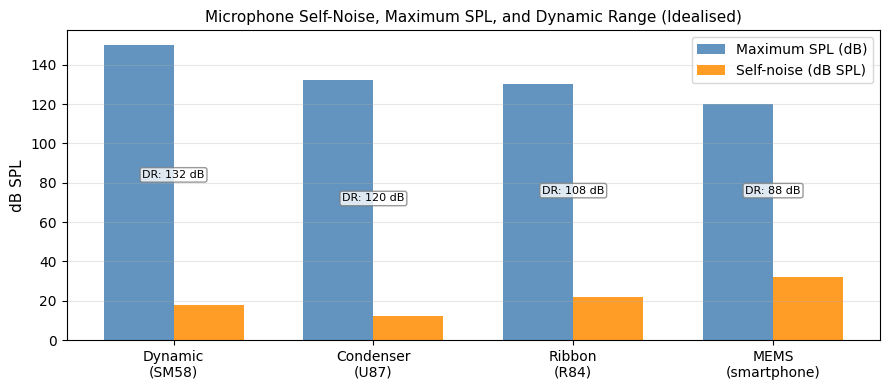
Chapter summary¶
Electroacoustics follows sound through transduction, gain staging, analogue and digital processing, and reproduction; microphones, loudspeakers, interfaces, and formats connect acoustic reality to the signal chains you use in recording, performance, and analysis.
Questions¶
- What is transduction, and how does it appear at both capture (microphones) and reproduction (loudspeakers)?
- How do microphone types and polar patterns shape what gets recorded in typical studio or stage setups?
- What are the main stages of a gain chain from mic to listener, and why does gain staging matter?
- How do sample rate, bit depth, and compression choices affect digital audio quality and workflow trade-offs?
- How do feedback, monitoring, and stereo or multi-mic techniques illustrate electroacoustic concepts in real scenarios?